Datomic as a Higher-Level Database
More than 20 years ago, when I first began learning programming languages, I read a line in a book:
C is a high-level language.
But it wasn't until years later, during a university class on assembly language, when I had to use jump commands just to write a loop, that I truly realized how high-level C was. Despite this, for much of my career, I found C to be quite low-level because I didn't want to deal with memory management via malloc and free, nor did I want to handle pointers. As my career progressed, I learned many programming languages. Java, for instance, was much higher-level than C because it provided garbage collection. Clojure, in turn, was even higher-level than Java because of its immutable collection types.
High-Level Doesn't Mean More Features — Sometimes It's the Opposite
High-level doesn't refer to having more features; it means higher-level semantics. As a result, high-level languages often restrict or even eliminate lower-level semantics. High-level semantics allow you to focus on specifying what you want to achieve without worrying about every single implementation detail—the machine handles those for you. In some cases, you’re even restricted from accessing certain details because they are easy to mess up.
For example, when writing in C, you are strongly discouraged from using jump commands; when writing in Java, you cannot directly manipulate pointers; when writing in Clojure, you are advised against using mutable collection types.
High-level semantics often come with a trade-off in terms of machine performance. The JVM’s garbage collection obviously uses extra memory, and Clojure’s immutable collection types also consume more memory compared to Java. Furthermore, Clojure's startup time far exceeds Java's, testing the limits of human patience and even spawning solutions like Babashka, specifically designed for shell usage.
High-level typically means trading machine efficiency for developer productivity, a trade-off that’s often worth it thanks to Moore’s Law, which ensures that machine performance will automatically improve over time.
In What Ways is Datomic High-Level?
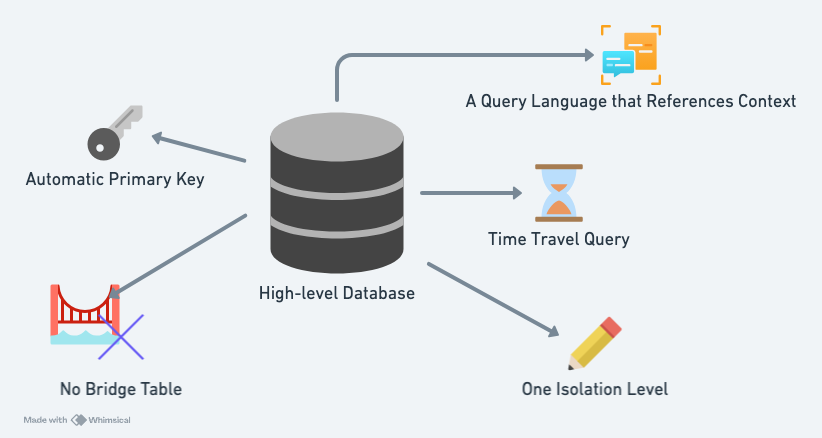
From my experience using Datomic, I've observed at least four ways in which it is a higher-level database:
- DDL (Data Definition Language)
- Primary Keys
- Many-to-Many Relationships
- Isolation Level
- Time-travel Queries
- A Query Language that References Context
DDL - Primary Keys
When working with SQL databases, I often struggled with how to design the primary key for my tables. The first decision to make is:
- Should I use a natural key, which is one or more data attributes derived from the business domain? This can be convenient early on, but sometimes not as good later.
- Should I use a surrogate key, which decouples the key from the business meaning, providing more flexibility for future modifications? Some tables, which represent parts of an entity that lack suitable natural keys, require surrogate keys.
If you decide to use a surrogate key, the next question is which data type to choose:
- Auto-incrementing integers
- UUIDs
Then, considerations about enumeration attacks and performance arise. Should you opt for integers that avoid enumeration attacks, or UUIDs that boost performance?
Datomic makes the primary key decision for you. In the world of Datomic, the primary key is the entity ID. It’s that simple. [1]
DDL - Many-to-Many Relationships
In SQL databases, when modeling many-to-many relationships, we usually need to design a bridge table.
In Datomic, there is no need for a bridge table because you can set the :db/cardinality attribute to :db.cardinality/many, which means the field supports one-to-many relationships. This feature not only simplifies the semantics by eliminating the need for a bridge table, but also makes the syntax for one-to-many and many-to-many relationships much more consistent.
Isolation Level
SQL databases offer four isolation levels:
- Read Uncommitted
- Read Committed
- Repeatable Read
- Serializable
These various levels exist to allow for higher performance when dealing with transactions. In contrast, Datomic only provides one isolation level—Serializable. [2] With fewer options, there is less for us to worry about.
Time-travel Queries
Traditional databases are like regular files; once something is written, you can’t go back to a previous state. Datomic is different. Its state is like a git repository, allowing you to easily revert to a previous state using a time-travel query known as the as-of query.
A Query Language that References Context
When writing SQL queries that involve multiple JOIN operations, the resulting query often becomes so long that it becomes hard to read. Human languages, in contrast, are typically composed of many short sentences. Short sentences can still convey complex ideas because they reference context. When we understand natural language, we don’t process each sentence in isolation; we use its context to fully grasp its meaning.
Datomic’s query language, Datalog, has a mechanism called Rules that can cleverly inject context into your queries.
Consider the following Datalog query, which retrieves the names of the actors in "The Terminator":
[:find ?name
:where
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title "The Terminator"]]
Now imagine that the part of the query responsible for "finding the actor's name from the movie title" is something you repeatedly write across different queries. Is there a way to avoid rewriting this section each time?
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]
Yes, and that mechanism is called Rules. We can rewrite the above query using Datomic Rules as follows:
;; The rules we defined
[(appear ?name ?title)
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]]
;; re-written Datolog Query
[:find ?name
:in $ %
:where (appear ?name "The Terminator")]
In this version, the appear rule abstracts the definition of an actor's "appearance" in a movie. Once this logical rule is applied by the query engine, the concept of "appearance" can be inferred as new knowledge.
This rule acts as a tool to reference context in a query. When a query language can reference context, it becomes more like human natural language, and thus more concise.
Envision a New Conversation
You recommend Datomic to your boss, and he/she asks, "What are its benefits? How can you prove it?"
You reply, "It improves productivity because it is a higher-level database."
I expect your boss will then ask, "What do you mean by higher-level?"
If the conversation is conducted thoughtfully and cleverly, this opening dialogue could lead to successfully advocating for the use of a higher-level database within your company. Savvy businesspeople may not remember or fully understand the various details of databases, but they understand that a higher level is equivalent to exchanging machine power for brain power. Exchanging something cheap for something expensive is a concept I believe businesspeople will understand.
Notes
-
[1] In practice, when using Datomic and needing to expose a unique identifier to the outside world, we typically design an additional UUID field. However, in this article, I won’t delve into all the design issues related to primary keys. My focus is: Datomic has already made the design decision for entity ID, which reduces the decisions we need to make, thus making this database more high-level.
-
[2] Most SQL database systems compose transactions from a series of updates, where each update changes the state of the database. However, Datomic transaction execution is not defined as a series of updates. It is defined as the addition of a set of datoms to the previous value of the database. Ref

Comments ()